

【Tesseract OCR下载】Tesseract OCR图片文字识别软件 v4.0 免费版
- 软件大小:查看
- 软件语言:简体中文
- 授权方式:免费软件
- 更新时间:2025-01-04
- 软件类型:国产软件
- 推荐星级:
- 运行环境:XP,Win7,Win8,Win10,Win11
软件介绍
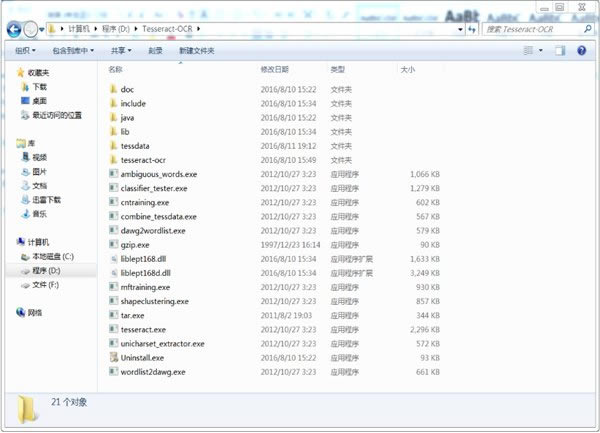
软件介绍Tesseract OCR是一款开源的ocr引擎,也可以看作是图像文字识别程序,它的主要功能就是帮助用户将图片中的文字内容识别出来,并将其转换成文本。Tesseract OCR使用起来很方便,不仅识别准确率高,而且识别的速度也很快,有需要的用户快来下载吧。 使用教程大体流程:Tesseract安装 -> 打开命令行 -> 生成目标文件 Tesseract安装 下载安装包,安装成功后会在相应磁盘下有Tesseract-OCR文件夹,如图
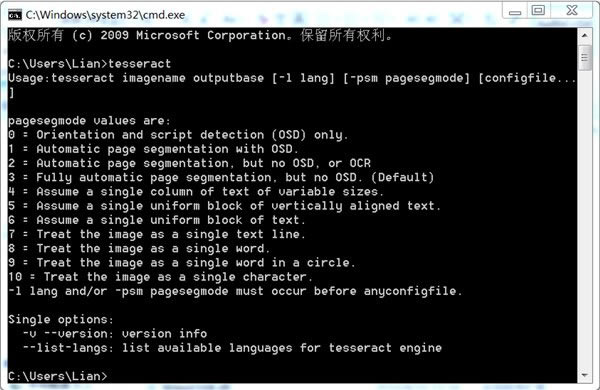
打开命令行 打开命令行,输入tesseract,回车;以下便是tesseract的大体面貌:
生成目标文件 先准备一张图片文件,如test.png
将命令行切换至目标图像文件目录,比如我们转换文件为test.png(图片文件允许多种格式),位于C:\Users\Lian\Desktop\test;然后在命令行中输入 tesseract test.png output_1 –l eng 【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…] imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng。
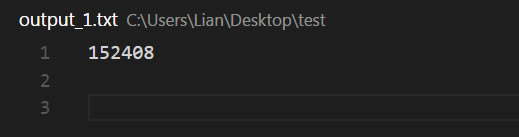
打开文件output_1.txt,发现tesseract成功的将图像转换成 152408 。
|
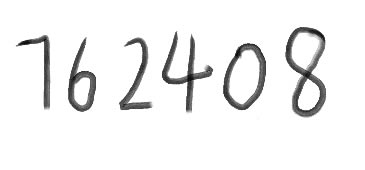

[温馨提示]:
本类软件下载排行
系统帮助教程
热门系统总排行